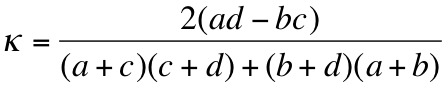
Authors: Milan Stakovic, Matthew Rowe
Version: 1.0
Date: 2011-04-11
Due to a high interest in reusing our methodology for reaching a satisfactory level of inter-rater agreement, and a demand in the research community for a comprehensive methodology guide, we have decided to publish this document with the intention to explain our methodology, justify its use and provide the guidelines for researchers who wish to apply it.
In constructing gold standard data sets, and performing other manual evaluations in which several (at least 3) experts give opinions, an important step is the measuring of inter-rater agreement, which if satisfactory, gives validity to the final results of rating.
The agreement levels between raters are usually calculated using the kappa (k) agreement metric, defined in [1], to calculate the evaluator agreement in each phase. The k-statistic measures the chance corrected agreement between raters, using the confusion matrix shown in Table 1. The metric presented here is used to express the agreement level between a pair of raters. Agreement level is considered satisfactory if the kappa value is greater then 0.6. The overall results are considered acceptable if the agreement between each two raters is satisfactory. Alternative metrics are available for calculating the agreement between more then two raters at once, but in this document we are using the two rater agreement measure for the sake of simplicity. Our methodology for reaching the satisfactory level of agreement however is independent of the metric used, and is therefore generalizable to other metrics.
Table 1. Rater Agreement Confusion Matrix for Two Raters
Rater 1 | |||
Positive | Negative | ||
Rater 2 | Positive | a | b |
Negative | c | d |
Kappa statistic
Reaching the satisfactory agreement between the expert raters is often difficult. Depending on the task, the inter-rater agreement can be quite low, especially if the task involves personal judgment and not just recognition of undeniable facts. Such personal judgment tasks are a common case in manual classification which leads to the need for a systematic way of reaching a satisfactory rater agreement, a level that would yield usable gold standards, and valid evaluations.
Our method consists of an iterative approach for reaching a satisfactory inter-rater agreement, inspired by Delphi method of forecasting [2]. The procedure for conducting the approach is as follows:
1. In the first step the raters are expected to give their ratings.
2. The ratings from the previous phase are then processed and the kappa statistic calculated. if the value of the kappa statistic is satisfactory for all rater pairs, accept the results and stop. If not, continue.
3. The rater inputs are anonymized and presented together. The order of presentation of raters inputs’ is randomized. Such ratings are then presented to all the raters who can then change their initial inputs, of if them disagree with the other raters he/she can input comments to justify their ratings. The comments remain anonymous in order to eliminate the potential source of bias in the weights one may give to other raters if their names were known.
4. go to step 2.
The approach helps to reach a satisfactory rater agreement if this is possible. If the array of kappa values would prove to be divergent, this would indicate the possibility that an agreement may not be reached with the given expert raters, and in such cases it is better to stop the procedure after 4th or 6th iteration.
We have successfully used the methodology in our studies [3] and [4] where the agreement was reached in less then 3 iterations, for 3 raters.
Stankovic-Rowe methodology allows one to surmount the problem of low inter-rater agreement in cases where the raters try to agree on a judgment rather then a fact. The method offers a way to correct a number of disagreements in ratings by reaching a consensus through controlled iterative interactions of raters. In these interactions the method assures that factors such as : raters’ reputation, image, sex, and age; as well as time of providing ratings; do not influence the consensus and the inter-rater agreement. The agreement is reached only through qualified justifications and convergence in opinion.
[1] Fleiss, J. L. (1981) Statistical methods for rates and proportions. 2nd ed. (New York: John Wiley)
[2] Rowe and Wright (1999): The Delphi technique as a forecasting tool: issues and analysis. International Journal of Forecasting, Volume 15, Issue 4, October 1999.
[3] Stankovic, M., Rowe, M., & Laublet, P. (2010). Mapping Tweets to Conference Talks: A Goldmine for Semantics. in Proceedings of the 3rd Social Data on the Web Conferece, SDOW2010, collcoated with International Semantic Web Conference ISWC2010. Shanghai, China.
[4] Stankovic, M., Jovanovic, J., & Laublet, P. (2011). Linked Data Metrics for Flexible Expert Search on the open Web. Poceedings of 8th Extended Semantic Web Conference (ESWC2011). Heraklion, Crete, Grece: Springer.